Problem
Given a statistical model \(P(\boldsymbol{X}, \boldsymbol{Z} | \boldsymbol{\theta})\), which generate set of observations \(\boldsymbol{X}\), where \(\boldsymbol{Z}\) is a latent variable and unknow parameter vector \(\boldsymbol{\theta}\). The goal is to find \(\boldsymbol{\theta}\) that maximize the marginal likelihood:
$$ \mathcal{L}(\boldsymbol{\theta}; \boldsymbol{X}) = P(\boldsymbol{X} | \boldsymbol{\theta}) = \int_{\boldsymbol{Z}}P(\boldsymbol{X}, \boldsymbol{Z} | \boldsymbol{\theta})d\boldsymbol{Z} $$
As an example for this type of problem, there are two (unfair) coin A and B with probability of head for each coin is \(p_A(H) = p \text{ and } p_B(H) = q\). For each trial, we select coin A with probability \(p(A) = \tau\) and coin B with probability \(p(B) = 1 -\tau\), toss the coin and record the observation. The set of observations \(\boldsymbol{X}\) is the record of head or tail \(\{H, T, H, H, \cdots\}\), the latent variable which is unobserved is which coint is selected for each trail \(\{A, B, B, A, \cdots\}\), and the unknown parameter vector \(\boldsymbol{\theta} = [p, q, \tau]\). The goal is to find \(\boldsymbol{\theta}\) that best fit observations; EM is an instance of Maximum Likelihood Estimation (MLE).
The EM algorithm
The algorithm
The EM algorithm seeks for \(\boldsymbol{\theta}\) by first initiates a random parameter vector \(\boldsymbol{\theta}^{(0)}\) and then iteratively performs two steps, namely the expectation step (E step) and the maximization step (M step):
- (The E step) the expected loglikelihood of \(\boldsymbol{\theta}\), with respect to the current conditional distribution of \(\boldsymbol{Z}\) given observations \(\boldsymbol{X}\) and current estimation of \(\boldsymbol{\theta}^{(t)}\)
$$ Q(\boldsymbol{\theta} | \boldsymbol{\theta}^{(t)}) = \mathbb{E}_{\boldsymbol{Z} \sim P(. | \boldsymbol{X}, \boldsymbol{\theta}^{(t)})} {[ \log P(\boldsymbol{X}, \boldsymbol{Z} | \boldsymbol{\theta}) ]} $$
- (The M step) update parameter vector \(\boldsymbol{\theta}\)
$$ \boldsymbol{\theta}^{(t+1)} = \arg\max_{\boldsymbol{\theta}} Q(\boldsymbol{\theta} | \boldsymbol{\theta}^{(t)}) $$
Proof of correctness
Setup
We need to proof that updating parameter vector \(\boldsymbol{\theta}\) by EM algorithm will monotonically increase the marginal likelihood of \(P(X|\theta)\)
$$ \log P(X|\theta^*) - \log P(X|\theta^{(t)}) \geq Q(\theta^* | \theta^{(t)}) - Q(\theta^{(t)} | \theta^{(t)}) \geq 0 $$ Where the second inequality come from \(\theta^* = \arg\max_\theta Q(\theta | \theta^{(t)}) \)
Proof
$$ \begin{aligned} & P(X, Z | \theta) = P(Z | X, \theta) P(X | \theta) & \text{\tiny(Bayes theorem)} \\ \iff & \log P(X, Z | \theta) = \log P(Z |X, \theta) + \log P(X |\theta) & \\ \iff & \log P(X | \theta) = \log P(X, Z | \theta) - \log P (Z | X,\theta) & \\ \implies & \log P(X | \theta) = \underbrace{ \mathbb{E}_{Z|X,\theta^{(t)}}{[\log P(X, Z | \theta)]} }_{Q(\theta | \theta^{(t)})} + \underbrace{ - \mathbb{E}_{Z|X,\theta^{(t)}}{[\log P(Z|X,\theta)]} }_{H(\theta | \theta^{(t)})} & \text{\tiny(taking expectation for both side)} \end{aligned} $$
So consider \(\log P(X|\theta) - \log P(X|\theta^{(t)})\) is the change in loglikelihood of observed data when we update the parameter vector \(\theta\)
$$ \begin{aligned} \log P(X|\theta) - \log P(X|\theta^{(t)}) & = Q(\theta|\theta^{(t)}) - Q(\theta^{(t)}|\theta^{(t)}) \\ & + \underbrace{H(\theta|\theta^{(t)}) - H(\theta^{(t)}|\theta^{(t)})}_{A} \\ \end{aligned} $$
Quantity \(A\)
$$ \begin{aligned} A & = - \mathbb{E}_{Z|X,\theta^{(t)}}{[\log P(Z|X,\theta)]} - \big( -\mathbb{E}_{Z|X,\theta^{(t)}}{[\log P(Z|X,\theta^{(t)})]} \big) \\ & = \mathbb{E}_{Z|X,\theta^{(t)}}{\bigg[ \log P(Z|X,\theta^{(t)}) - \log P(Z|X,\theta) \bigg]} \\ & = \int_{Z} P(Z|X,\theta^{(t)}) \log{\frac{P(Z|X,\theta^{(t)})}{P(Z|X,\theta)} dZ}\\ & \geq 0 &\text{\tiny(Gibb’s inequality)} \end{aligned} $$
So that
$$ \begin{aligned} \log P(X|\theta) - \log P(X|\theta^{(t)}) & = Q(\theta|\theta^{(t)}) - Q(\theta^{(t)}|\theta^{(t)}) + A \\ & \geq Q(\theta|\theta^{(t)}) - Q(\theta^{(t)}|\theta^{(t)}) & \square \end{aligned} $$
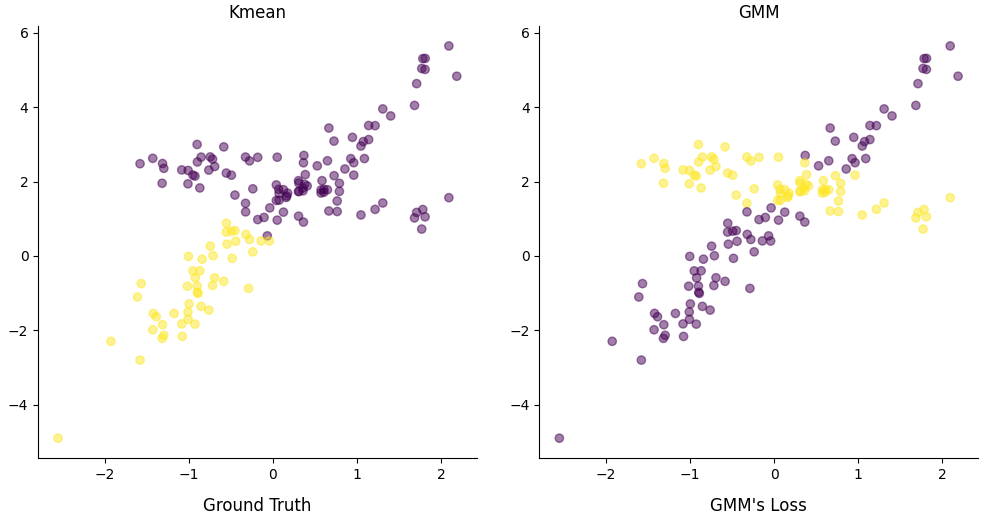
Examples
EM for the coin example
Setup
Parameter vector \(\boldsymbol{\theta} = [p, q, \tau]\), and its estimation at step (t) is \(\boldsymbol{\theta}^{(t)} = [p_t, q_t, \tau_t]\)
The \(i^{th}\) observation \(x^{(i)}\) is either head (H) or tail (T).
The coin selected for the \(i^{th}\) trail \(z^{(i)}\) is either A or B:
- \(p(z^{(i)} = A) = \tau\)
- \(p(z^{(i)} = B) = 1 -\tau\).
For both cases, $$ \begin{equation} p(z^{(i)}) = \tau^{\mathbb{I}(z^{(i)}=A)}(1-\tau)^{\mathbb{I}(z^{(i)}=B)} \end{equation} $$
When selected the coin A,
- Probability that we get a head (H): \(p(x^{(i)}=H | z^{(i)} = A) = p\)
- Probability that we get a head (T): \(p(x^{(i)}=T | z^{(i)} = A) = 1 - p\)
For both cases, $$ \begin{equation} p(x^{(i)} | z^{(i)}=A) = p^{\mathbb{I}(x^{(i)}=H)}(1 - p)^{\mathbb{I}(x^{(i)}=T)} \end{equation} $$
Similarly, when B is selected $$ \begin{equation} p(x^{(i)} | z^{(i)}=B) = q^{\mathbb{I}(x^{(i)}=H)}(1 - q)^{\mathbb{I}(x^{(i)}=T)} \end{equation} $$
Where \(\mathbb{I}(\cdot)\) is an indicator function on a predicate $$ \mathbb{I}(p) = \begin{cases} 1 \quad \text{if } p \text{ is True}\\ 0 \quad \text{otherwise} \end{cases} $$
Once again, we generalize for both cases of \(z^{(i)}\)
$$ \begin{equation} \begin{aligned} p(x^{(i)} | z^{(i)}) = [p^{\mathbb{I}(x^{(i)}=H)}(1 - p)^{\mathbb{I}(x^{(i)}=T)}]^{\mathbb{I}(z^{(i)}=A)}\\ \times [q^{\mathbb{I}(x^{(i)}=H)}(1 - q)^{\mathbb{I}(x^{(i)}=T)}]^{\mathbb{I}(z^{(i)}=B)} \end{aligned} \end{equation} $$
The equation looks rather ugly, we can simplify this by encoding head as 1 and tail as 0; coin A as 1 and coin B as 0. The equation above can be written as
$$ \begin{equation} p(x^{(i)} | z^{(i)}) = [p^{x^{(i)}}(1-p)^{1 - x^{(i)}}]^{z^{(i)}} [q^{x^{(i)}}(1-q)^{1 - x^{(i)}}]^{1-z^{(i)}} \end{equation} $$
Similarly for \(p(z^{(i)})\) $$ \begin{equation} p(z^{(i)}) = \tau^{z^{(i)}}(1-\tau)^{1-z^{(i)}} \end{equation} $$
Applying EM algorithm
The (E step):
- Construct the joint likelihood of a single pair of observation and latent variable \(p(x^{(i)}, z^{(i)})\ | \boldsymbol{\theta})\). For the conciseness, we drop the \((i)\) superscript from the equation.
$$ \begin{equation} \begin{aligned} p(x, z | \boldsymbol{\theta}) = & p(x | z, \boldsymbol{\theta})p(z | \boldsymbol{\theta})\\ = & [p^{x}(1-p)^{1 - x}]^{z} [q^{x}(1-q)^{1 - x}]^{1-z} \tau^{z}(1-\tau)^{1-z} & \text{\tiny(from eq. 5 and 6)} \end{aligned} \end{equation} $$
Likelihood over entire observations \(\boldsymbol{X}\) and latent \(\boldsymbol{Z}\):
$$\boldsymbol{X}\odot\boldsymbol{Z} := \{(x^{(i)}, z^{(i)})\}_{i=1\cdots N}$$
A side note is that I am not entirely sure that \(\odot\) operator is appropriate in this situation.
$$ \begin{equation} \begin{aligned} P(\boldsymbol{X}, \boldsymbol{Z} | \boldsymbol{\theta}) =& \prod_{(x, z) \in \boldsymbol{X}\odot\boldsymbol{Z}} { p(x, z | \boldsymbol{\theta}) } \end{aligned} \end{equation} $$
Log likelihood of the joint probability
$$ \begin{equation} \begin{aligned} \log P(\boldsymbol{X}, \boldsymbol{Z} | \boldsymbol{\theta}) & = \sum_{(x, z)} \log p(x, z | \boldsymbol{\theta}) \end{aligned} \end{equation} $$
Taking a log always seem to make thing to be better.
Finally, we need to take the expectation of the log likelihood w.r.t conditional probability of \(\boldsymbol{Z}|\boldsymbol{X}, \boldsymbol{\theta}^{(t)}\)
Posterior for a single latent \(z\)
$$ \begin{equation} \begin{aligned} p(z | x, \boldsymbol{\theta}^{(t)}) & = \frac{p(x, z | \boldsymbol{\theta}^{(t)})} {p(x | \boldsymbol{\theta}^{(t)})} & \text{\tiny(Bayes Theorem)}\\ & = \frac{p(x, z | \boldsymbol{\theta}^{(t)})} { p(x, z = 0| \boldsymbol{\theta}^{(t)}) + p(x, z = 1| \boldsymbol{\theta}^{(t)}) } & \text{\tiny(Marginal likelihood over z in denominator)}\\ & = \frac{ [p_t^{x}(1-p_t)^{1 - x}]^{z} [q_t^{x}(1-q_t)^{1 - x}]^{1-z} \tau_t^{z}(1-\tau_t)^{1-z} }{ q_t^{x}(1-q_t)^{1 - x} (1-\tau_t) + p_t^{x}(1-p_t)^{1 - x}\tau_t } & \text{\tiny(from eq. 7)} \end{aligned} \end{equation} $$
Taking the expectation
$$ \begin{equation} \begin{aligned} Q(\boldsymbol{\theta} | \boldsymbol{\theta}^{(t)}) &= \mathbb{E}_{\boldsymbol{Z} | \boldsymbol{X}, \boldsymbol{\theta}^{(t)}}{\bigg[ \sum_{(x, z)}{\log p(x, z | \boldsymbol{\theta})} \bigg]} \\ &= \sum_{(x, z)} { \mathbb{E}_{\boldsymbol{Z} | \boldsymbol{X}, \boldsymbol{\theta}^{(t)}}{[ \log p(x, z | \boldsymbol{\theta}) ]} } \\ &= \sum_{(x, z)} { \mathbb{E}_{z | x, \boldsymbol{\theta}^{(t)}}{[ \log p(x, z | \boldsymbol{\theta}) ]} } \\ \end{aligned} \end{equation} $$
It is always bothering for me that in literature, the posterior, of which to be taken expectation over, for the entire set latent variables \(\boldsymbol{Z} = \{ z^{(1)}, \cdots z^{(n)}\}\) can be replaced by the posterior for a single latent \(z\) in (eq. 11) without explanation. So in order to understand this, consider the equation.
$$ \begin{aligned} \mathbb{E}_{\boldsymbol{Z}}{\bigg[\sum_{z\in \boldsymbol{Z}}{f(z)}\bigg]} &= \int_{\boldsymbol{Z}}{ \bigg[\sum_{z\in\boldsymbol{Z}} f(z)\bigg] p(\boldsymbol{Z}) d\boldsymbol{Z} } \\ & = \sum_{z\in\boldsymbol{Z}}{\int_{\boldsymbol{Z}}{f(z)}} p(\boldsymbol{Z})d\boldsymbol{Z} \\ & = \sum_{z\in\boldsymbol{Z}}{ \int_{\boldsymbol{Z}\text{/}z} \underbrace{\bigg[\int_{z}f(z)p(z)dz\bigg]}_{A=\mathbb{E}_z[f(z)]} p(\boldsymbol{Z}\text{/}z)d(\boldsymbol{Z}/z) } \\ & = \sum_{z\in\boldsymbol{Z}} A \int_{\boldsymbol{Z}\text{/}z} p(\boldsymbol{Z}\text{/}z)d(\boldsymbol{Z}/z) & \text{\tiny(A is constant w.r.t variable being integrated over)} \\ & = \sum_{z\in\boldsymbol{Z}} \mathbb{E}_z[f(z)] & \text{\tiny(Integerating over a p.d.f evalulated to 1)} \end{aligned} $$
Where \(\boldsymbol{Z} = \{z^i\}_{i=1\cdots N}; z \sim p(Z)\); \(\boldsymbol{Z}/z\) denotes set all variables within \(\boldsymbol{Z}\) except \(z\).
Having clear that up, we are able to resume from (eq. 11) $$ \begin{equation} \begin{aligned} Q(\boldsymbol{\theta} | \boldsymbol{\theta}^{(t)}) &= \sum_{(x, z)} { \mathbb{E}_{z | x, \boldsymbol{\theta}^{(t)}}{[ \log p(x, z | \boldsymbol{\theta}) ]} } \\ &= \sum_{(x, z)} {\bigg[ p(z = 0 | x, \boldsymbol{\theta}^{(t)}) \log p(x, z = 0 | \boldsymbol{\theta}) \ + p(z = 1 | x, \boldsymbol{\theta}^{(t)}) \log p(x, z = 1 | \boldsymbol{\theta}) \bigg]} \end{aligned} \end{equation} $$
From (eq. 7)
- $$ \begin{aligned} p(x, z = 0 |\boldsymbol{\theta}) = q^x(1-q)^{1-x}(1-\tau) \end{aligned} $$
- $$ \begin{aligned} p(x, z = 1 |\boldsymbol{\theta}) = p^x(1-p)^{1-x}\tau \end{aligned} $$
From (eq. 10)
$$ \begin{aligned} p(z = 0 | x, \boldsymbol{\theta}^{(t)}) & = \frac{ q_t^{x}(1-q_t)^{1-x}(1-\tau_t) }{ q_t^{x}(1-q_t)^{1 - x} (1-\tau_t) + p_t^{x}(1-p_t)^{1 - x}\tau_t } \end{aligned} $$
$$ \begin{aligned} p(z = 1 | x, \boldsymbol{\theta}^{(t)}) & = \frac{ p_t^{x}(1-p_t)^{1-x}\tau_t }{ q_t^{x}(1-q_t)^{1 - x} (1-\tau_t) + p_t^{x}(1-p_t)^{1 - x}\tau_t } \end{aligned} $$
This probability is often referred as membership probability, denote the membership probability of the \(i^{th}\) observation \(p(z^{(i)} = 0 | x^{(i)}, \boldsymbol{\theta}^{(t)}) = a_i\) and \(p(z^{(i)} = 1|x^{(i)},\boldsymbol{\theta}^{(t)}) = 1 - a_i\). With this
Substitute these quantities into eq. 12 we have the expectation of the log-likelihood w.r.t conditional probability of \(\boldsymbol{Z}\) given observations and current state of the parameters.
$$ \begin{aligned} Q(\boldsymbol{\theta} | \boldsymbol{\theta}^{(t)}) = \sum_{i=1}^{N}{ a_i [x^{(i)}\log q + (1-x^{(i)})\log(1-q) + \log(1-\tau)] } \\ + (1 - a_i)[x^{(i)} \log p + (1-x^{(i)})\log (1-p) + log\tau] \end{aligned} $$
The M step $$ \boldsymbol{\theta}^{(t+1)} = \arg\max_{\boldsymbol{\theta}}{Q(\boldsymbol{\theta} | \boldsymbol{\theta}^{(t)})} $$
\(\frac{\partial Q}{\partial p} = 0 \)
$$ \begin{aligned} & \frac{\partial Q}{\partial p} = 0 \\ \iff & \sum_{i=1}^N{(1-a_i)[\frac{ x^{(i)}}{p}} - \frac{1-x^{(i)}}{1-p}] = 0 \\ \iff & \frac{1}{p} \underbrace{\sum_{i=1}^N{(1-a_i)x^{(i)}}}_{A} = \frac{1}{1-p} \underbrace{\sum_{i=1}^N{(1-a_i)(1-x^{(i)})}}_{B} \\ \implies & p = A/(A+B) \\ & = \color{red}{\frac{\sum_{i=1}^N{(1-a_i)x^{(i)}}}{\sum_{i=1}^N{(1-a_i)x^{(i)}}+\sum_{i=1}^N{(1-a_i)(1-x^{(i)})}}} \end{aligned} $$
\(\frac{\partial Q}{\partial q} = 0 \), same with \(p\)
$$ \begin{aligned} \color{red}{ q = \frac{\sum_{i=1}^N{a_i x^{(i)}}}{\sum_{i=1}^N{a_i x^{(i)}}+\sum_{i=1}^N{a_i(1-x^{(i)})}} } \end{aligned} $$
\(\frac{\partial Q}{\partial \tau} = 0 \) $$ \begin{aligned} & \frac{\partial Q}{\partial \tau} = 0 \\ \iff & \sum_{1}^N{\frac{-a_i}{1-\tau} + \frac{1-a_i}{\tau}} = 0\\ \iff & \frac{1}{1-\tau}\sum_{1}^N{a_i} = \frac{1}{\tau}\sum_{i=1}^N{(1-a_i)}\\ \implies & \color{red}{\tau = \frac{\sum_{i=1}^N{1-a_i}}{N}} \end{aligned} $$